特点
- 本地私有大模型,无限制次数,并且想问啥都行,保证隐私;
- 想用任何开源模型都行,你自己封装的也可,例如Llama3,通义千问Qwen-32b,Yi……;
- 沉浸式翻译无限制使用;
- 需要一定的硬件内存,也可以不需要GPU,CPU可运行。
部署步骤
可参考官方Ollama-linux.md 62,详细如下:
下载
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama sudo chmod +x /usr/bin/ollama
创建用户
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama
开机自启
sudo vim /etc/systemd/system/ollama.service
填入如下
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_ORIGINS=*" # My added Environment="OLLAMA_HOST=0.0.0.0" # My added [Install]
WantedBy=default.target
Then start the service:
启动Service
sudo systemctl daemon-reload sudo systemctl enable ollama
启动Ollama,运行模型
sudo systemctl start ollama
ollama run yi-6b.Q5_K_M
命令行可以输入进行聊天了,需要UI界面的可看配置Open-WebUI部分或者文末的 Other Ollama+中的浏览器插件。
注意事项
添加环境变量
相比官方安装步骤,对于ollama.service,不同点在于:增加行Environment="OLLAMA_ORIGINS=*"允许实现跨域请求,不加,沉浸式翻译会报403错误;增加行Environment="OLLAMA_HOST=0.0.0.0" 。
关闭开机自启动
Ollama后台运行,一直会占用几百M显存,不经常用的话,可以关闭ollama.service服务开机自启动。
sudo systemctl disable ollama
每次需要启动时
sudo systemctl start ollama
判断内存适合多大模型
估算:4精度7b模型大概需要3.5G,4G更好。
可参考模型参数和内存的计算方式
大模型落地的量化技术 23
Ollama library 中模型名没有写量化后缀的模型,基本上是4精度的,模型下边都有量化精度介绍,例如Llama3 19中的
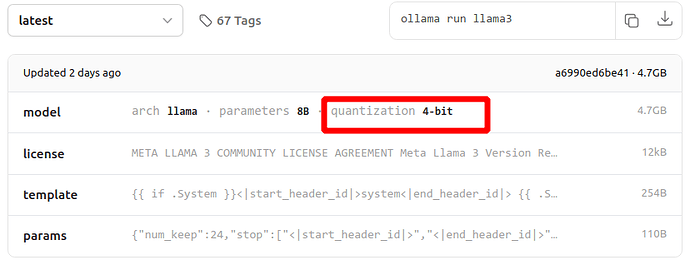
也可以参考Yi模型页面的硬件要求
Yi-34B 20
导入非Ollama Library中的模型
写makefile来导入模型。进入你下载的.gguf 模型的文件夹。模型来源:huggingface 4,hf-mirror 1 ,modelscope或者自己手撮的模型…
cd /home/lihua/mymodels
例如下载的模型为yi-6b.Q5_K_M.gguf,新建makefile文件
vim yi-6b.Q5_K_M.gguf.mf
填入
FROM ./yi-6b.Q5_K_M.gguf
TEMPLATE """[INST] <<SYS>>{{ .System }}<</SYS>>
{{ .Prompt }} [/INST]
"""
PARAMETER stop "[INST]" PARAMETER stop "[/INST]" PARAMETER stop "<<SYS>>" PARAMETER stop "<</SYS>>"
需要有TEMPLATE和PARAMETER部分,否则模型会出错。
生成ollama支持的模型方式:
ollama create yi-6b.Q5_K_M -f yi-6b.Q5_K_M.gguf.mf
导入成功,运行模型:
ollama run yi-6b.Q5_K_M
设置仅CPU中运行
(base) li@linux:~$ ollama run yi-6b.Q5_K_M >>> /? >>> /set >>> /set parameter Available Parameters: /set parameter seed <int> Random number seed /set parameter num_predict <int> Max number of tokens to predict /set parameter top_k <int> Pick from top k num of tokens /set parameter top_p <float> Pick token based on sum of probabilities /set parameter num_ctx <int> Set the context size /set parameter temperature <float> Set creativity level /set parameter repeat_penalty <float> How strongly to penalize repetitions /set parameter repeat_last_n <int> Set how far back to look for repetitions **/set parameter num_gpu <int> The number of layers to send to the GPU** /set parameter stop "<string>", ... Set the stop parameters >>> /set parameter num_gpu 0 >>> /save yi-6b.Q5_K_M
查看模型和更改模型目录
查看当前所有安装的模型
ollama list
查看yi-6b.Q5_K_M的modelfile,其中包含模型路径
ollama show --modelfile yi-6b.Q5_K_M
修改路径
sudo systemctl edit ollama.service
增加行
Environment="OLLAMA_MODELS=/home/li/myollama/"
加载和重启ollama
sudo systemctl daemon-reload sudo systemctl restart ollama
查看实时 log
journalctl -e -f -u ollama
不要用ollama serve 命令启动模型
ollama serve默认以当前用户启动模型,会运行第二个ollama进程,重复下载模型,产生第二个模型路径。请采用sudo systemctl start ollama启动,会以之前默认新建的用户运行模型。
不要以docker方式运行Ollama
以docker方式运行Ollama,当导入非Ollama Library中的模型时,需要把模型从host传入到docker中,或者挂载makefile和下载的模型目录,非常不方便。建议采用以上的Linux Manual install安装方式。
应用
Open-WebUI
Open-WebUI人机界面配置,需要你安装了docker,有的话可以跳过以下这一步
安装docker
卸载旧版
for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done
安装
# Add Docker's official GPG key: sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc # Add the repository to Apt sources: echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd docker-buildx-plugin docker-compose-plugin
验证是否成功
sudo docker run hello-world
非root权限运行
sudo groupadd docker sudo usermod -aG docker $USER newgrp docker
docker run hello-world
部署 Open-WebUI
运行
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
打开 http://localhost:3000 12,登录注册,可以到UI界面了,选择模型就可以享用了。
Immersive Translate
沉浸式翻译,非常好的翻译应用,可以配置如下
翻译服务:
OpenAI
自定义 API Key:
ollama
模型:
yi-6b.Q5_K_M
自定义 API 接口地址:
http://localhost:11434/v1/chat/completions
Other Ollama+
UI
Open WebUI 20
Lobe 3
Page Assist 浏览器插件 6